[논문리뷰] M2m: Imbalanced Classification via Major-to-minor Translation (2/2)
3. Experiments
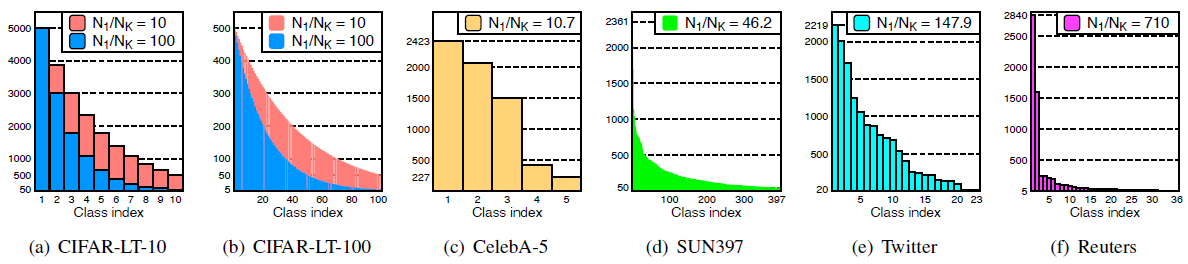
우리는 이렇게 만들어진 모델을 CIFAR-10/100, ImageNet-LT, CelebA, SUN397, Twitter, Reuter dataset과 같이 다양한 class-imbalanced classification task로 평가해보았다. Figure 3은 실험에 사용된 데이터셋의 class-wise sample distribution을 나타낸다. balanced test distribution에서 모델의 classification 성능을 평가하기 위해 우리는 기하평균과 산술평균에 해당하는 balanced accuracy (bACC)와 geometric mean score (GM)의 2가지 방법을 사용했다.
3.1. Experimental setup
Baseline methods: 우리는 다음과 같은 다양한 범위의 baseline method를 고려했다. (a) empirical risk minimization (ERM), (b) re-sampling (RS), (c) SMOTE, (d) re-weighting (RW), (e) class-balanced re-weighting (CB-RW), (f) deferred re-sampling (DRS), (g) deferred re-weighting (DRW), (h) focal loss (Focal), (i) label-distribution-aware margin (LDAM). 대략적으로 baseline은 다음의 세 가지 카테고리로 나뉜다. (i) "re-sampling" based methods - (b, c, f), (ii) "re-weighting" based methods - (d, e, g), (iii) different loss functions - (a, h, i)
Training details: 모든 모델은 stochastic gradient descent (SGD)로 학습되었고, 이때 momentum of weight = 0.9로 설정했다. 초기 learning rate는 0.1로 설정했고, 학습 중 learning rate가 줄어드는 "step decay"를 적용하였다. 또한 더욱 효과적인 학습을 위해 첫 5번의 epoch에서는 "linear warm-up" learning rate strategy를 사용하였다.
Details on M2m: 본 모델을 적용할 때 우리는 주어진 dataset에 대해 standard ERM training으로 학습된 classifier $g$를 사용하며, ERM training이 모두 진행된 후에 적용을시작한다. hyperparameter의 경우 $\beta \in \{0.9, 0.99, 0.999\}$, $\lambda \in \{0.01, 0.1, 0.5\}$, $\gamma \in \{0.9, 0.99\}$에서 선택하였고, $T=10$, $\eta=0.1$로 설정하였다.
3.2. Long-tailed CIFAR datasets
우리는 imbalanced dataset에 대해 모델을 평가하기 위해 "synthetically long-tailed" variant를 갖는 CIFAR dataset을 고려할 것이다. imbalanced ratio $\rho>1$을 갖는 long-tailed distribution은 다음의 조건을 만족한다. (a) $\frac{N_1}{N_K} = \rho$이고, (b) $N_1$과 $N_K$ 사이의 $N_k$는 exponential하게 감소한다. 우리는 각각의 CIFAR-LT-10/100에 대해 $\rho \in \{10, 100\}$인 경우를 고려했는데, sample distribution은 Figure 3(a)와 3(b)에서 찾아볼 수 있다. 아래의 Table 1은 주요 결과를 보여주는데, 전체적으로 우리의 방법이 다른 baseline 모델에 비해 bACC를 크게 향상시켰다는 것을 확인할 수 있다.

3.3. Real-world imbalanced datasets
다음으로는 naturally imbalanced dataset인 CelebA, SUN397, Twitter, Reuters 데이터셋을 이용해보았다. 데이터의 분포는 Figure 3에서 확인해볼 수 있다. 결과를 나타내면 Table 2와 같은데, 여기서도 마찬가지로 M2m이 다른 baseline method에 비해 더욱 좋은 성능을 낸다는 것을 확인할 수 있다.

3.4. Ablation study
제시한 방법에 대한 상세한 분석을 위해 광범위한 실험을 수행하였다. 이 섹션의 모든 실험은 imbalanced ratio $\rho = 100$인 CIFAR-LT-10에서 ResNet-32 모델을 사용하여 수행되었다. 또한 각 class에 어떤 변화가 생기는지 파악하기 위해 majority와 minority class에 대한 테스트 정확도를 "Major"와 "Minor"로 이름을 붙여 표기하였다. 모든 class를 "majority"와 "minority"로 나눴는데, majority class는 $\sum_k N_k$가 전체의 50%가 넘도록 하는 $k$에 대해 top-$k$ frequent class에 해당하고 minority class는 나머지 class이다.
Diversity on seed samples: 2.1절에서는 우리의 방법이 majority sample의 다양성을 활용하여 minority class에 대한 over-fitting을 방지하는 데서 비롯되었다고 가정했다. 이를 확인하기 위해 우리는 "seed sample"의 수를 다르게 하여 실험을 진행해보았다. Table 3를 보면 minority class의 정확도가 seed sample pool이 다양해짐에 따라 점진적으로 증가함을 확인할 수 있다. 이는 M2m이 minority class에 대한 over-fitting을 방지하기 위해 majority class의 다양성을 활용한다는 것을 나타낸다.

The effect of $\lambda$: M2m 생성 단계의 optimization objective (2)에 synthetic sample의 품질을 개선하기 위해 regularization term $\lambda \cdot f_{k_0}(x)$를 부과하는데, 이는 생성된 샘플이 $f$의 관점에서 여전히 기존 class의 중요한 feature를 포함할 수 있기 때문이다. 이 term의 효과를 확인하기 위해 $\lambda$를 0으로 설정하는 실험을 고려하고, 성능을 원래 방법과 비교해보았다. Table 4는 제시된 regularization의 효과가 있었다는 것을 보여주고 있다.

Over-sampling from the scratch: 3.1절에서 설명한 바와 같이 우리의 방법에는 기본적으로 "deferred" scheduling이 사용된다. 즉, 일정한 epoch 수의 표준 ERM 훈련 후에 방법을 적용하기 시작한다. 비교를 위해 이 전략을 사용하지 않는 "M2m-RS" 케이스를 고려하였다. Table 4는 M2m-RS가 (Table 1의) DRS와 DRW를 제외한 다른 모든 기준을 능가한다는 것을 보여주며, 이는 우리의 방법이 효과적임을 보여주고 있다.
Labeling as a targeted class: pre-trained classifier $g$에 대한 주요 가정은 $g$ 자체가 minority class에 대해 잘 일반화될 필요가 없다는 것이다. 이는 $g$를 사용하여 (2)를 해결하더라도, 생성된 샘플이 target minority class의 generalizable feature를 포함하지 않을 수 있다는 것을 의미한다. 생성된 샘플이 target class와 얼마나 관련되어 있는지 확인하기 위해 M2m-RS에 대한 다른 실험을 고려하였다. 생성된 샘플을 대상 및 원래 클래스를 제외한 모든 가능한 클래스 중에서 "random" 클래스로 레이블링하는 이 방법을 "M2m-RS-Rand"라고 할 때, Table 4에 나와 있는 결과는 M2m-RS-Rand가 M2m-RS보다 minority class에서의 성능이 훨씬 나쁘다는 것을 보여준다.
Comparison of t-SNE embeddings: 효과를 더 검증하기 위해 t-SNE를 사용하여 다양한 훈련 방법에서 학습한 penultimate feature를 시각화하고 비교하였다. 각 임베딩은 CIFAR-LT-10 ($\rho=100$)에서 무작위로 선택된 훈련 샘플의 하위 집합에서 계산되어 각 클래스당 50개의 샘플로 구성되었다. Figure 4는 그 결과를 보여주는데, M2m 임베딩에서는 (minority class임에도 불구하고) 각 군집을 성공적으로 구분할 수 있는 반면 다른 방법들은 일부 모호한 영역을 가지고 있음을 보여준다.

Comparison of cumulative false positive: Figure 5는 class 1부터 class $K$까지 집계한 cumulative false positive (FP) 샘플 수가 어떻게 증가하는지 그래프로 나타낸다. 이를 식으로 표현하면 $\sum_k FP_k$이고, 여기서 $FP_k$는 테스트 세트에서 class $k$로 잘못 분류된 샘플의 수를 나타낸다. CIFAR-LT-10/100의 balanced test set로 각 그래프를 계산하며, 잘 훈련된 classifier는 선형에 가까운 그래프를 보일 것이다. 전반적으로, M2m에 해당하는 그래프는 다른 그래프보다 일관적으로 낮고 선형적이다. 이는 우리의 방법이 더 적은 false positive를 만들어내고, 더 나아가 이들이 class에 더 균일하게 분포되어 있다는 것을 시사한다.

The use of adversarial examples: 2.2절에서 M2m으로 생성된 샘플은 종종 원본에 매우 가까운 synthetic minority sample로 끝나는 것을 언급했다. 이는 여기에서 가정한 대로 $f$와 $g$가 neural network인 경우, 즉 ResNet-32인 경우에 발생한다. Figure 6이 이러한 경우의 대표적인 예시이다. 이런 adversarial perturbation이 우리의 방법에 어떤 영향을 미치는지 더 잘 이해하기 위해 "M2m-Clean"이라고 하는 간단한 실험을 고려하였다. 이 방법은 majority sample $x_0$에서 minority sample $x^*$을 합성하는 대신 "clean" $x_0$를 사용하여 over-sampling한다. 동일한 훈련 설정에서, Table 4에서 확인할 수 있듯이 M2m-Clean의 balanced accuracy가 원래 M2m과 비교하여 상당히 감소하는 것을 알 수 있다. 이는 작은 노이즈를 포함한 경우에도 adversarial perturbation이 우리의 방법을 작동하게 만드는 데 극히 중요하다는 것을 보여다.

4. Conclusion
본 논문에서는 imbalanced classification에 대해 새로운 over-sampling 방법인 Major-to-minor Translation (M2m)을 제시하였다. 우리는 pre-trained classifier를 사용한 간단한 변환으로 majority sample의 다양성이 class-imbalanced training을 크게 돕는다는 것을 발견했다. 이는 오랜 기간 동안 지속된 class-imbalanced problem을 극복하기 위한 방법으로 여겨지며, CycleGAN과 같이 Major-to-minor 변환을 탐구하는 것은 흥미로운 연구 주제가 될 것이라 생각된다. 본 논문에서 탐구한 문제들은 또한 adversarial perturbation이 좋은 특성이 될 수 있는지에 대한 중요한 질문을 던지고 있다. 우리의 결과는 적어도 imbalanced learning을 위한 목적에서는 adversarial perturbation이 좋은 특성이 될 수 있다는 것을 시사한다. 우리는 본 연구가 imbalanced learning과 adversarial example에 대한 연구의 새로운 방향을 열 수 있다고 믿는다.
총평: KAIST에서 나온 논문이어서 더욱 유심히 봤던 것 같다. 확실히 diffusion model 관련 논문보다는 수식이 적어서 읽는 데 큰 어려움은 없었던 것 같다. 거의 모든 내용을 어느 정도 수긍하면서 읽었는데, 마지막에 결과를 보여주는 파트가 아쉬웠다. majority class에서 minority sample을 만든다는 내용인데, Figure 6을 보면 거의 똑같은 사진을 다른 개념으로 해석하고 있어서 이건 classifier를 잘못 설정한 게 아닌가 하는 의문이 들기도 한다. 한편으로는 내가 논문 내용을 잘못 이해한 건가 싶기도 해서, 이 논문과 관련해서는 토의를 좀 더 해봐야 할 필요가 있을 것 같다.