3. Basic Findings of LIFT
main finding을 요약하자면 다음과 같다.

3.1. How Well Does LIFT Perform on Standard ML Tasks?
Classification: Table 4에서는 다양한 알고리즘에 대한 classification accuracy를 비교하고 있다. 표에서 $p$는 feature의 수, $c$는 data class의 수를 의미한다. 표를 보면 LIFT가 대부분의 baseline에 대해 동등한 성능을 발휘하며, 거의 모든 케이스에 대해 LIFT/GPT가 top 3 안에 드는 것을 확인할 수 있다. 또한 logistic regression과 비교해봤을 때, LIFT는 non-linear relationship을 더욱 잘 학습한다는 것을 알 수 있다. LIFT는 feature의 수가 많을 때에도 비교적 잘 수행되지만, class의 수가 많은 경우 다른 baseline에 비해 낮은 accuracy를 갖게 된다. 예를 들어 100-class Margin dataset에서 LIFT/GPT-J와 best algorithm (RBF-SVM) 간의 accuracy gap은 거의 30%이다. 이는 baseline은 feature scaling과 normalization을 통해 좋은 성능을 얻을 수 있지만 LIFT는 raw data를 직접적으로 사용하기 때문에 나타나는 결과라고 볼 수 있다.

Regression: Table 19는 function approximation comparison을 보여주고 있다. 표에서 결과값은 RAE value이고, $p$는 feature의 수를 의미한다. $p=1, 2$의 low-dimensional case에서는 LIFT가 baseline과 비슷한 성능을 보이지만, 예측값과 실제값의 근사 정도를 측정하는 것이 아닌 token 간의 비교로 오차를 측정하는 GPT model인 GP와 같은 강력한 baseline을 능가하지는 못한다. 이러한 성능 문제는 numerical value을 binary value으로 표현하는 level encoding을 통해 개선할 수 있다고 추측하고 있다.

3.2. How Many Samples Does LIFT Need?
Fig.25는 classification 및 regression task에 대한 sample complexity evaluation을 보여준다. GPT 모델이 LIFT를 사용하여 새로운 작업을 빠르게 학습할 수 있는 것을 발견하였다. classification의 경우 class의 수가 증가할수록 (Fig.25a의 왼쪽에서 오른쪽으로 이동할수록) LIFT는 적응을 위해 더 많은 샘플을 필요로 하는데, 이는 데이터의 입력 및 출력 공간이 더 복잡하여 학습하기 어렵기 때문일 것으로 추정된다. regression의 경우 LIFT가 작은 RMSE를 갖기 위해서는 1000개의 샘플이면 충분하다는 것을 발견하였고, cosine이나 piecewise function의 경우 LIFT가 popular baselines보다 낮은 sample complexity를 갖는다는 것을 확인했다.

3.3. Language-Interfaced Learning: LIFT versus In-Context Learning (ICL)
LIFT를 포함한 language-interfaced learning framework는 새로운 작업에 대한 fine-tuning 없이 몇 개의 training example에 의존하여 inference을 수행하는 In-Context Learning (ICL)을 포함한 다른 학습 방법에도 사용될 수 있다. Table 5는 (a) ICL, (b) n개의 샘플로 학습된 LIFT, 그리고 (c) 전체 데이터셋으로 학습된 LIFT 간의 classification performance를 비교한다. 여기서 ICL에 사용되는 training sample의 수(n)는 주어진 LM의 context 길이에 따라 달라진다. 전체 데이터셋을 사용한 LIFT는 항상 최상의 성능을 달성하지만, 동일한 training sample 수를 사용할 때 LIFT/Subset과 ICL은 대부분의 경우에서 비슷한 결과를 보인다.

3.4. Can We Understand the Inductive Biases of Language Models via LIFT?
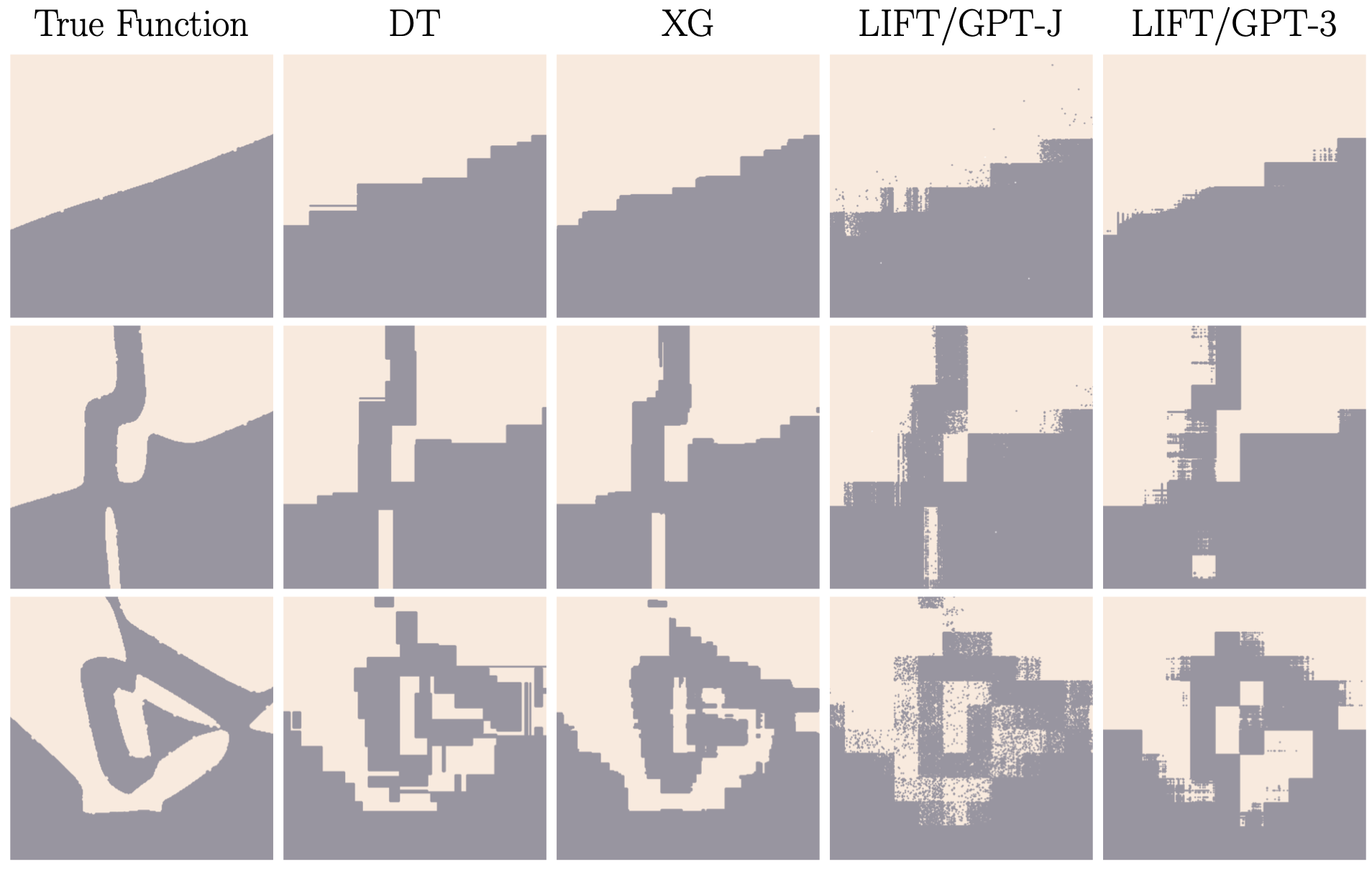
LIFT/GPT 모델의 inductive bias를 더 잘 이해하기 위해, classification decision boundary를 Fig.6과 같이 complexity를 다양하게 하여 조사해보았다. 먼저 binary-class neural network를 훈련시키고 서로 다른 training epoch에서의 snapshot을 사용하여 decision boundary의 complexity level이 다른 dataset을 만들었다. (Fig.6의 첫 번째 열) 이때 LIFT/GPT model이 세 가지 boundary에 잘 적응되어 rough shape를 capture한 것을 확인하였다. 또한 boundary shape는 tree-based classifier의 boundary와 유사하게 axis-parallel하다는 것도 확인되었다. 뿐만 아니라 이를 관찰했을 때 convolution neural network와 비슷하게 fractal을 찾아볼 수 있었다.
3.5. How Robust is LIFT?
training data의 outlier sample과 test data의 feature corruption을 토대로 LIFT의 robustness를 조사했다.
Robustness to outliers in training data: outcome $y$가 대부분의 sample $(\mathbf{x}, y)$에서 일치하지 않고 outlier를 갖는 regression task를 고려했을 때, Fig.28a는 outlier가 있는 경우와 없는 경우의 RAE value를 비교한다. (training set에서 2%의 outliers) 이 경우 baseline은 큰 성능 저하를 겪는 반면, LIFT/GPT model은 성능에는 거의 영향을 받지 않는 가장 robust한 model임을 알 수 있다. 또한, Fig.28b는 다양한 outlier (1%, 2%, 5%, 10%, 20%)에 대해 model을 평가한 결과를 나타낸 것이다. robust baselines (median-3NN, median-5NN)과 비교했을 때 LIFT/GPT-3은 비교적 robust하며, LIFT/GPT-J는 more outlier에 대해서는 취약하다는 것을 파악할 수 있다.

Robustness to feature corruption on test data: feature $\mathbf{x}$와 label $y$를 갖는 clean test data $(\mathbf{x}, y)$가 주어졌을 때, feature에 small perturbation $\mathbf{\delta}$가 추가되어 왜곡된 데이터 $(\mathbf{x} + \mathbf{\delta}, y)$에 대한 LIFT의 정확도를 측정했다. Table 33은 random noise와 PGD attack에 대한 MNIST classification에서의 robustness result를 보여준다. perturbation radious는 $\epsilon$ ∈ [0, 0.01, 0.1, 0.3]로 설정되며, MNIST pixel value는 [0, 1]의 범위 내에 있다. 이때 비교 대상이 되는3개의 네트워크는 LeNet-5, MLP, 그리고 LIFT/GPT-3이다. $\epsilon$ ∈ {0.01, 0.1}인 경우 LIFT/GPT-3을 관찰해보면 random noise에 대해서는 큰 변화가 없지만 PGD attack에 대해서는 accuracy가 많이 떨어지는 것을 확인할 수 있다.

3.6. Does LIFT Need Large-Scale Models Pretrained on Natural Language Data?
LIFT가 잘 수행되는 pretrained LM의 requirement를 조사하기 위해 다양한 유형의 LM에 대한 LIFT 변환을 비교했다. 이때 사용된 LM으로는 natural language data로 pretrained된 GPT (본 연구의 model), pretraining을 거치지 않은 large LM (Rand-GPT-J), programming language data로부터 학습된 CodeParrot과 CodeGen-2B-mono와 같이 non-human language data로부터 pre-trained된 LM, 그리고 무의미한 데이터로 fine-tuned된 GPT-J가 있다.
Does LIFT only need a large pretrained model? 이 질문에 답하기 위해, pretrained GPT와 randomly initialized GPT-J에 대한 LIFT의 성능을 비교하였다. Table 8에 나타난 결과를 보면, 모든 dataset에 대해 LIFT/Rand-GPT-J의 정확도가 LIFT/GPTs보다 훨씬 낮은 것을 알 수 있다. 이 결과는 LIFT가 pretraining에서 이점을 얻는다는 것을 의미하며, 단순히 large-scale design of LM이 이점을 얻는 것은 아니라는 것을 나타낸다.
Does LIFT need a model trained on natural language data? Table 8에 나타난 결과에 따르면, 모든 dataset에서 LIFT/GPTs가 LIFT/CodeGen 및 LIFT/CodeParrot보다 훨씬 우수한 성능을 보인다. 이는 LIFT가 natural language data로 pretrained된 LM과 함께 더 좋은 성능을 발휘할 수 있다는 것을 나타낸다. pretrained된 GPT-J가 gibberish data로 fine-tuned된 경우, 몇몇 task에 대한 accuracy가 하락하여 전반적으로 LIFT/GPTs보다 낮아지는 것을 알 수 있다. 그러나 LIFT/Gibberish는 여전히 상당히 좋은 성능을 보이며, LIFT/GPT-J와의 성능 차이는 large pretrained LM에 대한 fine-tuning의 영향으로 인해 발생한다. 따라서 LIFT에는 natural language data에 대한 pretraining이 필수적이다.




