지금까지 tabular data와 관련된 여러 논문을 읽어왔는데, 아직 tabular data에 대한 개념이 제대로 정립되지 않은 것 같아서 한번 짚고 넘어가봐야 할 필요가 있을 것 같다. 이 논문은 tabular data가 유독 타 데이터 도메인에 비해 deep learning이 먹히지 않는 현상에 대해 관찰한 논문이다.
1. Introduction
deep neural network는 이미지, 오디오, 텍스트 등 다양한 분야에서 큰 성공을 거두었다. 각 분야에서는 raw data를 의미 있는 값으로 인코딩하기 위한 몇 가지 대표적인 아키텍처가 있는데, 이들은 실전에서 우수한 성능을 발휘한다.
실제로로 가장 일반적인 데이터 유형은 tabular data로, sample(행)은 그에 대응되는 feature(열)를 갖는다. tabular data는 의학, 금융, 제조업, 기상 예보 등 다양한 분야에서 사용되며, relational database를 기반으로 하는 업무에 주로 적용된다. 지난 10년 동안 기존의 기계 학습 방법인 gradient-boosted decision trees (GBDT)와 같은 방법은 tabular data modeling에서 딥러닝보다 우수한 성능을 보여주었다. 반면 deep neural network는 tabular data에 적용될 때 lack of locality, data sparsity, mixed feature types 및 데이터셋 구조에 대한 lack of prior knowledge 등의 많은 어려움을 겪는다. 또한 deep neural network는 "black box" 접근법으로 인식되는데, 이는 입력 데이터가 모델 출력으로 어떻게 변환되는지에 대한 투명성이나 해석 가능성이 부족하다는 것을 의미한다. "no free lunch" principle은 항상 적용되지만, XGBoost와 같은 tree-ensemble algorithm이 실제 tabular data problem에 권장되는 선택지로 여겨진다.
최근에는 tabular data에 대한 deep network를 개발하려는 시도가 여러 차례 이루어졌고, 그 중 일부는 GBDT보다 우수한 성능을 보였다고 주장되기도 한다. 그러나 이 분야의 각 연구는 서로 다른 데이터셋을 사용했기 때문에 tabular data model을 정확하게 비교하는 것은 어려웠다. 또한 일부 연구들은 이러한 모델들을 동일하게 최적화하지 않았다. 따라서 딥러닝 모델이 tabular data에 대해 GBDT를 능가하는지, 그리고 어떤 딥러닝 모델이 최고의 성능을 발휘하는지에 대한 결론이 불분명하다. 이러한 불분명함은 연구 및 개발 과정을 방해하며, 이러한 논문들의 결론을 명확하게 이해하는 데 어려움을 준다. 딥러닝을 tabular data에 적용하는 논문 수가 증가함에 따라, 우리는 이 분야의 최근 동향을 철저히 검토하고 연구의 기반이 될 보다 구체적인 결론을 제공하는 것이 시기적절하다고 판단했다. 본 연구의 주요 목적은 최근 제안된 deep model 중 어떤 모델이 tabular dataset problem에 적합한지 조사하는 것이고, 이는 다음의 두 질문으로 평가한다. (1) 논문에 등장하지 않은 데이터셋에 대해서도 모델들이 더 정확한가? (2) 훈련 및 hyperparameter 검색에 소요되는 시간은 다른 모델들과 비교하여 어떤가?
이러한 질문에 답하기 위해 우리는 최근 제안된 딥러닝 모델과 XGBoost를 다양한 tabular dataset에서 동일한 tuning protocol로 평가한다. 우리는 최근 네 논문에서 제안된 deep model을 11개의 데이터셋에서 평가하였고, 이 중 9개는 해당 논문에서 사용된 데이터셋이었다. 연구 결과, 대부분의 경우 각 deep model은 각각의 논문에서 사용된 데이터셋에서 가장 우수한 성능을 발휘하지만 다른 데이터셋에서는 상당히 낮은 성능을 보였다. 또한 본 연구는 XGBoost가 일반적으로 이러한 데이터셋에서 deep model보다 우수한 성능을 보인다는 것을 보여주었고, XGBoost에 대한 hyperparameter 검색 과정이 훨씬 더 빨랐음을 입증하였다. 우리는 deep model과 XGBoost를 결합한 앙상블의 성능을 검토하였고, 이 앙상블이 최상의 결과를 제공한다는 것을 보여주었다. 이것은 XGBoost가 없는 deep model의 앙상블이나 classical model의 앙상블보다 우수한 성능을 발휘한다.
물론, 어떤 tabular dataset의 선택이 이 데이터 유형의 다양성을 전부 대표한다고 볼 수는 없으며, "no free lunch" principle은 어떤 모델도 항상 다른 모델보다 우수하거나 나쁘지 않다는 것을 의미한다. 그러나 우리의 체계적인 연구는 최근의 중요한 진전에도 불구하고 현재 딥러닝이 tabular data에 필요한 모든 것을 제공하지 않는다는 점을 보여주고 있다.
2. Background
GBDT와 같은 classical machine learning method는 우수한 성능으로 tabular data application에서 주도적인 역할을 하기 때문에 연구자들과 실무자들은 XGBoost, LightGBM, CatBoost를 포함한 여러 GBDT 알고리즘을 사용한다. GBDT는 출력을 예측하기 위해 일련의 weak learner를 학습한다. GBDT에서 weak learner는 standard decision tree로, differentiablility가 부족하지만 많은 작업에서 유사한 성능을 보인다.
XGBoost 모델: XGBoost 알고리즘은 extendible gradient boosting tree 알고리즘으로, 많은 tabular dataset에서 좋은 결과를 달성한다. gradient boosting은 새로운 모델을 이전 모델의 residual로부터 생성하고, 이후 이 모델들을 결합하여 최종 예측을 만드는 알고리즘이다. 새로운 모델을 추가할 때 손실을 최소화하기 위해 gradient descent algorithm을 사용하며, XGBoost는 가장 인기 있는 GBDT 구현 중 하나이다.
2.1. Deep Neural Models for Tabular Data
앞서 언급한 대로, 최근 연구들은 tabular data에 딥러닝을 적용하고 새로운 neural architecture를 도입하여 향상된 성능을 달성했다. 이러한 모델들은 크게 두 가지 주요 카테고리로 나뉜다.
- Differentiable trees: tabular data에서 decision tree 앙상블의 성능이 우수하기 때문에 이러한 decision tree를 differentiable하게 만들 수 있다. 원래 decision tree는 미분 불가능해서 gradient 최적화를 허용하지 않으므로 end-to-end training pipeline의 구성 요소로 사용할 수 없다. 이 문제를 해결하기 위해 몇 가지 연구들은 internal tree node의 decision function를 smoothing함으로써 미분 가능하게 하고, tree function와 tree routing을 미분 가능하게 만드는 방법을 찾고 있다.
- Attention-based models: 다양한 분야에서 널리 사용되고 있으며, 몇몇 저자들은 tabular deep network에 attention-like module을 적용하는 것을 제안했다. 최근 연구에서는 datapoint 간의 상호 작용을 나타내는 inter-sample attention과 주어진 샘플의 feature가 전체 행(샘플)을 사용하여 상호 작용하는 intra-sample attention을 제안했다.
이러한 모델들은 서로 다른 benchmark로 평가되었기에 서로 비교되지 않았다. 최근에 제안된 tabular data 학습을 위한 deep model 중에서는 TabNet, NODE, DNF-Net, 그리고 1D-CNN이 있다. 이들은 트리 앙상블을 능가하여 주목을 끈 4가지 모델로, 주요 아이디어는 다음과 같다.
- TabNet: TabNet은 여러 데이터셋에서 잘 동작한 딥러닝 end-to-end model이다. TabNet은 인코더를 포함하며, 순차적인 결정 단계에서 sparse learned mask를 사용하여 feature를 인코딩하고, mask를 사용하여 각 행마다 관련 있는 feature을 선택한다. 인코더는 sparsemax layer를 사용하여 소수의 feature을 선택하도록 한다. mask를 학습시킴으로써 feature에 대해 유동적인 결정을 할 수 있어서 기존의 (미분 불가능한) feature 선택 방법을 완화시킨다.
- Neural Oblivious Decision Ensembles (NODE): NODE network는 미분 가능하게 만든 동일한 깊이의 oblivious decision tree (ODT)를 포함한다. ODT는 미분 가능하게 만들어져 error gradient가 backpropagate를 통해 업데이트될 수 있다. 기존의 decision tree와 마찬가지로 ODT는 선택된 feature에 따라 데이터를 분할하고, 각각의 feature를 학습된 값과 비교한다. 그러나 한 번에 하나의 feature만 선택하므로 균형 잡힌 ODT를 얻을 수 있고, 이로 인해 미분이 가능해져 완전한 모델은 미분 가능한 트리들의 앙상블을 제공한다.
- DNF-Net: DNF-Net의 아이디어는 deep neural network에서 Disjunctive Normal Formula (DNF)를 시뮬레이트하는 것이다. 논문의 저자들은 hard Boolean formula을 미분 가능한 버전으로 대체하는 것을 제안했다. 이 모델의 주요 특징은 disjunctive normal neural form (DNNF) block으로, (1) a fully connected layer와 (2) binary conjunctions으로 이루어진 DNNF layer를 포함한다. 완전한 모델은 이러한 DNNF들의 앙상블이다.
- 1D-CNN: 최근에, 1D-conventional neural network (CNN)가 tabular data와 함께 Kaggle 경연에서 최상의 single model performance를 달성했다. 이 모델은 CNN 구조가 feature 추출에서 잘 동작하지만 tabular data에서는 feature ordering에 locality characteristic이 없기 때문에 거의 사용되지 않는다는 아이디어에 기반한다. 이 모델에서는 feature의 locality characteristic을 가진 더 큰 feature set를 만들기 위해 완전히 연결된 layer가 사용되며, 이후 몇 개의 1D-Conv 레이어가 shortcut과 같은 연결로 이어진다.
2.2. Model Ensemble
앙상블 학습은 모델의 성능을 향상시키고 분산을 줄이는 데 널리 사용되는 방법이다. 이는 여러 개의 모델을 동일한 작업을 해결하기 위해 훈련시키고, 그들의 예측을 결합하여 최종 결과를 얻는 것을 목표로 한다. 다른 모델들의 장점을 활용함으로써 앙상블은 더 안정적이고 정확한 예측을 제공한다. 앙상블은 주로 두 가지 유형으로 나뉜다. 첫 번째는 random forest와 같이 randomization을 기반으로 한 방법으로, 기본 학습자들이 독립적으로 훈련된다. 두 번째는 boosting을 기반으로 한 접근법으로, 기본 학습자들이 순차적으로 훈련되어 이전 모델들의 오류를 수정한다. 전반적으로 앙상블 학습은 다양한 모델들을 활용하고 그들의 예측을 결합함으로써 모델의 성능을 향상시킨다.
본 연구에서, 우리는 앙상블에 TabNet, NODE, DNF-Net, 1D-CNN, XGBoost의 5개의 classifier를 사용했고, 앙상블을 만들기 위해 두 가지 다른 버전을 제시했다.
(1) 앙상블을 uniformly weighted mixture model로서 다음과 같이 결합하는 방법

(2) 각 모델에 대해 weighted average를 적용하여 결합하는 방법 - 이때 $l_k^{val}$은 $k$번째 모델의 validation loss이다.
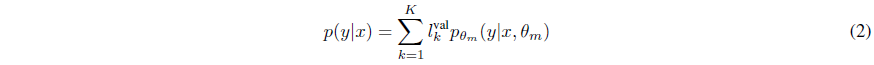
3. Comparing the Models
우리는 제안된 deep model이 다양한 tabular dataset에 사용될 경우의 장점을 조사하였다. 실제 응용에서는 모델들이 (1) 정확하게 동작하고, (2) 효율적으로 훈련 및 추론이 가능하며, (3) 최적화 시간이 짧아야 한다. 따라서 우리는 먼저 deep models, XGBoost, 그리고 앙상블의 성능을 다양한 데이터셋에서 평가했다. 이후 앙상블의 다른 구성 요소를 분석한 다음 앙상블을 위해 어떻게 모델을 선택하는지 조사하고, deep model이 좋은 결과를 만드는 데 필수적인지 아니면 'classical' model (XGBoost, SVM, CatBoost)을 결합하는 것만으로도 충분한지 테스트하였다. 또한 정확성과 계산 리소스 요구 사항 사이의 균형을 탐색했으며, 서로 다른 모델들의 hyperparameter 탐색 과정을 비교하고 XGBoost가 deep model보다 우수한 성능을 보여줌을 보여주었다.
3.1. Experimental Setup
3.1.1. Data-sets Description
여기서부터는 간략하게 흐름만 훑으면서 넘어가도록 하겠다. 본 연구에서 사용된 데이터셋은 다음과 같다.

3.1.2. Implementation Details
The Optimization Process: 모델의 hyperparameter를 선택하기 위해 Bayesian optimization을 사용하는 HyperOpt를 적용하였다.
Metrics and evaluation: binary classification problem에 대해서는 cross-entropy loss를 측정했고, regression problem에는 root mean square error를 측정했다.
Statistical significance test: 신뢰도 95%의 구간을 측정하여 표기하였다.
Training: 100번의 epoch로 모델을 훈련시켰다.
3.2. Results
Do the deep models generalize well to other datasets?
Table 2는 각 데이터셋에 대한 모델의 성능을 loss로 표현한 값을 나타낸 것이다.
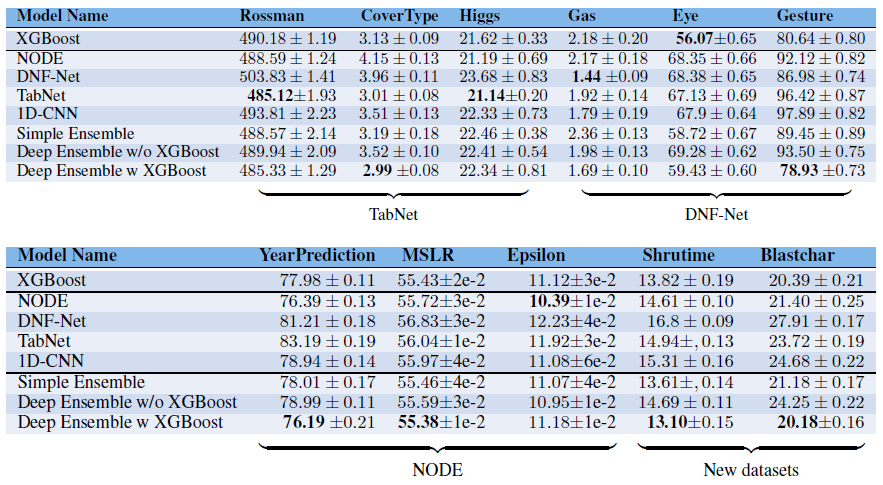
여기서 우리는 다음과 같은 사실을 관찰할 수 있다.
- 대부분의 경우, 모델은 논문에서 평가했던 데이터가 아닌 다른 데이터셋에 대해 좋지 않은 성능을 보인다.
- 다른 deep model과 비교했을 때 XGBoost가 더 좋은 성능을 보인다.
- 어떤 deep model도 일관적으로 다른 모델보다 우수한 성능을 보여주지 않는다. 각 deep model은 해당 논문에 포함된 데이터셋에서만 더 나은 성능을 보였다.
- deep model과 XGBoost의 앙상블은 대부분의 경우 다른 모델들보다 우수한 성능을 보인다. 11개의 데이터셋 중 7개에서 앙상블 모델이 single deep model보다 좋은 성능을 보여줬다.
다른 모델들 간의 직접적인 비교를 위해, 각 데이터셋마다 해당 데이터셋에서 가장 우수한 모델과 비교하여 각 모델의 상대적인 성능을 계산했다. Table 3은 각 모델의 unseen dataset에서의 상대적인 성능의 평균을 나타낸 것이다.

원래 논문에 포함되지 않은 데이터셋에서 훈련한 결과, deep model은 XGBoost보다 성능이 떨어졌다. XGBoost와 전체 앙상블과 비교했을 때, single deep model의 성능은 특정 데이터셋에 훨씬 민감하게 반응했다. deep model이 보지 못한 데이터셋에서 훈련할 때 성능이 떨어지는 이유에는 여러 가지 가능성이 있다. 첫 번째 가능성은 selection bias로, 각 논문에서 해당 모델이 잘 작동하는 데이터셋을 찾아 모델의 성능을 표현했을 수 있다. 두 번째 가능성은 optimization of hyperparameter의 차이이다. 해당 논문에 제시된 데이터셋을 기반으로 더 확장된 hyperparameter 탐색을 수행했다면 더 나은 성능을 얻을 수 있었을 것이다.
Do we need both XGBoost and deep networks?
우리는 XGBoost와 deep model의 앙상블이 데이터셋 전체에서 가장 우수한 성능을 보였음을 확인했다. 이 결과로부터 XGBoost를 deep model과 결합해야 하는지, 아니면 보다 간단한 nondeep model의 앙상블만으로도 유사한 결과를 얻을 수 있는지에 대한 궁금증이 생겼다. 이를 조사하기 위해, XGBoost와 다른 nondeep model (SVM, CatBoost)의 앙상블을 훈련했다. Table 2에서 보듯이, classical model의 앙상블은 deep network와 XGBoost의 앙상블보다 훨씬 성능이 떨어졌다. 또한, 표는 XGBoost 없이 deep model만으로만 구성된 앙상블의 결과값이 좋지 않았음을 보여준다. 이는 deep model과 XGBoost를 결합하는 것이 이러한 데이터셋에서 이점을 제공한다는 것을 나타낸다.
Subset of models
우리는 앙상블이 성능을 향상시켰지만, 여러 모델을 사용할 경우 추가적인 계산이 필요하다는 것도 관찰할 수 있었다. 실제 응용에서는 이를 계산하는 것이 최종적인 모델 성능에 영향을 미칠 수 있기에, 우리는 성능과 계산 사이의 균형을 탐색하기 위해 앙상블 내에서 모델의 subset을 사용하는 것을 고려했다.
앙상블에서 모델의 subset을 선택하는 여러 가지 방법이 있다. (1) validation loss을 기반으로, 먼저 validation loss가 낮은 모델을 선택하는 방법, (2) 모델의 uncertainty for each example을 기반으로, 각 예제에 대해 가장 높은 신뢰도를 가진 모델을 선택하는 방법, 그리고 (3) random order를 기반으로 하는 방법이 있다.
Figure 1은 unseen dataset (Shrutime)에 대해 모델 선택 방법에 따른 loss를 그래프로 표현한 것으로, validation loss를 기반으로 선택하는 것이 가장 좋은 방법임을 확인할 수 있었다. 반면 모델을 random order로 선택하는 것은 가장 좋지 않은 선택이었다.

How difficult is the optimization?
Figure 2는 Shrutime dataset에 대한 hyperparameter 최적화 프로세스의 반복 횟수에 따른 모델의 성능을 보여준다. 우리는 XGBoost가 deep model보다 우수한 성능을 빠르게 수렴하여 좋은 성능을 보였다는 것을 관찰했다. 이러한 결과는 여러 요소에 영향을 받을 수 있다. (1) 우리는 Bayesian hyperparameter optimization process를 사용했으며, 다른 최적화 프로세스에서 결과가 다를 수 있다. (2) XGBoost의 initial hyperparameter가 더 robust할 수 있습니다. 다른 데이터셋으로 측정한다면 deep model에서 더 잘 작동하는 initial hyperparameter를 찾을 수도 있다. (3) XGBoost 모델은 더 견고하고 최적화하기 쉽다는inherent characteristic을 가질 수 있다.

4. Discussion and Conclusions
이 연구에서는 최근 제안된 deep model이 tabular dataset에 대해 어떻게 성능을 보이는지 조사하였다. 분석 결과, deep model은 원래 논문에 포함되지 않은 데이터셋에서는 성능이 약하였으며, 기준 모델인 XGBoost보다도 성능이 떨어졌다. 따라서 우리는 이러한 deep model과 XGBoost의 앙상블을 제안하였다. 이 앙상블은 individual model 및 'non-deep' classical ensemble보다 이러한 데이터셋에서 더 나은 성능을 보였다. 또한, 실제 응용에서 중요한 performance, computational inference cost, hyperparameter optimization time을 연구했다. 분석 결과, 보고된 deep model의 성능은 그대로 받아들이기는 힘들다는 결론을 얻었다. 우리가 다른 데이터셋에서 성능을 비교했을 때, 모델들로부터 얻은 결과는 좋지 않았다. 또한, 새로운 데이터셋에 대해 deep model을 최적화하는 것은 XGBoost보다 훨씬 어렵다는 단점도 있다. 하지만 우리는 XGBoost와 deep model의 앙상블이 우리가 조사한 데이터셋에서 가장 좋은 결과를 제공한다는 것을 발견했다.
결과적으로, 연구자들이 실제 응용에서 모델을 선택할 때는 여러 가지 요소를 고려해야 한다. 시간 제약이 있는 상황에서는 XGBoost가 최고의 결과를 얻고 최적화하기 쉽다. 그러나 XGBoost만으로는 최고의 성능을 달성하기 어려울 수 있으며, 성능을 극대화하기 위해서는 deep model을 앙상블에 추가하는 게 좋을 것이다. tabular data에 대해 deep model을 사용한 연구들은 상당한 진전을 보였지만 우리가 조사한 데이터셋에서는 XGBoost보다 성능이 더 좋지 않았기에 이 분야에서 더 많은 연구가 필요할 것으로 보인다. 우리의 발전된 앙상블 결과는 더 많은 연구 가능성을 제시한다.
총평: 지금까지 읽었던 논문은 자신들이 연구실에서 만들어낸 모델을 소개하면서 '우리 모델 잘났어요~' 하고 소개하는 내용이라면, 이 논문은 다른 논문을 냉철하게 비판하고 저격하는 논문이다. 처음 읽어보는 류의 논문이어서 꽤 흥미롭게 읽었다. 지금까지는 논문을 읽으면서 이상하다고 생각되도 그냥 읽기에 급급해서 대충 받아들이면서 넘어갔는데, 이렇게 신랄하게 비판하는 논문을 보니 앞으로는 나도 냉철한 시각을 가지고 논문을 읽어야겠다는 생각이 들었다. 물론 아직은 그럴 짬이 아니고 지식과 실력이 더 쌓여야 가능하겠지만... 갈 길이 멀어도 한참 먼 것 같다.
'논문리뷰' 카테고리의 다른 글
| [논문리뷰] Deep State Space Models for Time Series Forecasting (1/2) (0) | 2023.07.30 |
|---|---|
| [논문리뷰] Learning Loss for Active Learning (1/2) (0) | 2023.07.27 |
| [논문리뷰] Chain of Hindsight Aligns Language Models with Feedback (0) | 2023.07.25 |
| [논문리뷰] Language Models are Realistic Tabular Data Generators (0) | 2023.07.23 |
| [논문리뷰] SOS: Score-based Oversampling for Tabular Data (2/2) (0) | 2023.07.21 |



